Dein SIEM ist nicht zu teuer. Deine Datenstrategie ist es.

Jedes Quartal das gleiche Spiel: Die SIEM-Renewal landet auf dem Tisch des CFO, und plötzlich ist Cybersecurity wieder ein Kostenproblem. Aber was in diesem Meeting niemand hören will: Das Tool ist nicht das Problem. Es ist die Art, wie ihr es füttert.
Das Volumen an Machine Data wächst um 25–35% pro Jahr. Security-Budgets stagnieren. Diese Lücke schließt sich nicht von allein. Und trotzdem reagieren die meisten Unternehmen so, wie sie es immer getan haben: mehr ingestieren, mehr bezahlen und hoffen, dass irgendjemand downstream herausfindet, was davon eigentlich nützlich ist.
Wird nicht passieren. Nicht bei diesem Volumen.
Das "Dump & Pray" Anti-Pattern
Nennen wir es, wie es ist. Die meisten Unternehmen behandeln ihr SIEM wie eine digitale Mülldeponie. Jeder Log, jeder Trace, jede harmlose DNS-Query landet im selben hochpreisigen Indexer. Keine Priorisierung. Kein Intent. Nur Volumen.
Wir sehen dieses Muster in fast jedem Engagement. Die Konsequenzen sind vorhersehbar:
Ihr bezahlt Premium-Preise, um Heuhaufen zu lagern, nicht um Nadeln zu finden. In einem kürzlichen Assessment bei einem Finanzdienstleister mit rund 400 GB/Tag Ingestion haben wir festgestellt, dass über 60% der indexierten Daten reines Rauschen waren: Health Check Pings, Load Balancer Keep-Alives, Debug-Level Application Logs, DHCP Lease Renewals. Alles im Hot Tier bei €2,50/GB. Macht rund €800K pro Jahr an Ingestion-Kosten für Daten, die kein Analyst jemals abfragt.
Eure Analysten ertrinken, statt zu ermitteln. Wenn alles "wichtig" ist, ist nichts wichtig. Die Teams, mit denen wir arbeiten, berichten durchgehend, dass 70%+ ihrer Zeit ins Filtern von Rauschen geht, bevor überhaupt Triage beginnen kann. Das ist kein Personalproblem. Das ist ein Architekturproblem.
Ihr seid locked-in, ohne es zu merken. Wenn alle eure Daten in einem proprietären Format eines einzelnen Vendors liegen, werden Wechselkosten existenziell. Wir haben Unternehmen gesehen, die kritische Plattformentscheidungen um 18+ Monate verschoben haben, weil sie ihre eigenen Daten nicht extrahieren konnten. Das ist keine Partnerschaft. Das ist eine Abhängigkeit.
Anfangen beim Outcome, nicht bei den Daten
Die Lösung ist nicht, ein weiteres Tool zu kaufen. Die Lösung ist, die Reihenfolge zu ändern. Statt alles zu sammeln und im Nachhinein Use Cases aus dem Datenhaufen zu reverse-engineeren, stellt ihr eine einfache Frage: Welche Entscheidung muss dieses Datum unterstützen?
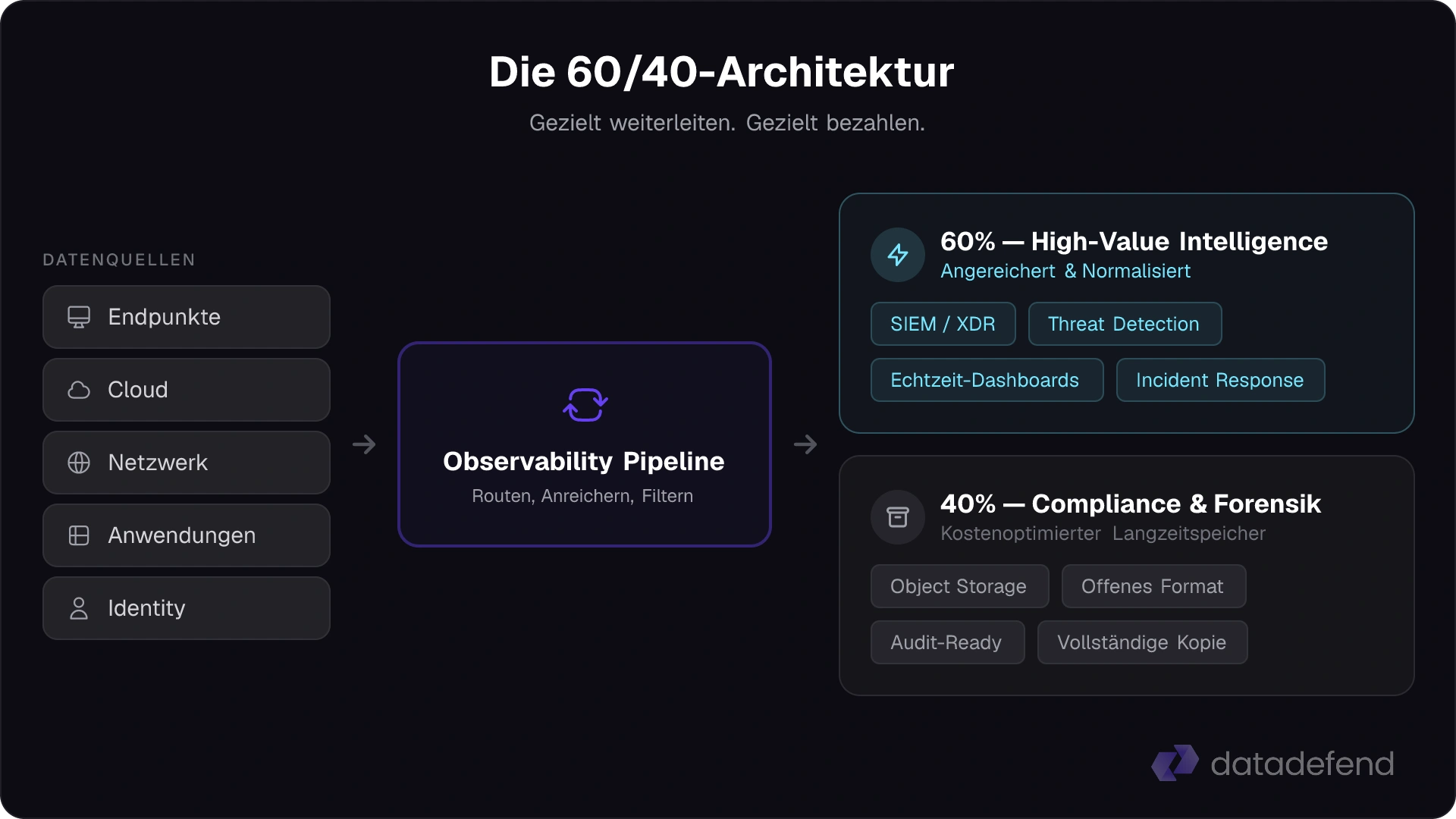
Das ist der Shift hin zu dem, was die Branche als Observability Pipeline bezeichnet: ein intelligenter Routing Layer zwischen euren Datenquellen und euren Zielsystemen. Stellt es euch als Control Plane für eure Machine Data vor. Bevor irgendetwas in einem Indexer landet, wird es klassifiziert, angereichert und basierend auf seinem tatsächlichen Zweck geroutet.
In der Praxis setzen wir das als strategischen Split um:
~40%: Compliance & Forensic Archive. Das ist "Checkbox-Data." Wichtig für Auditoren, Regulatoren und Legal Holds, aber ohne Wert für Real-Time Detection. Wir routen diese Daten in kostengünstigen, offenen Object Storage. Volle Fidelity, voll durchsuchbar, aber zu einem Bruchteil der Ingestion-Kosten. S3-kompatibler Storage bei €0,02/GB statt €2,50/GB im SIEM.
~60%: High-Value Intelligence. Das sind die Daten, die eure Analysten tatsächlich brauchen: angereichert, normalisiert, dedupliziert und in einem Format geliefert, das für Entscheidungen bereit ist, nicht fürs Parsen. Threat-relevante Logs. Korrelierte Security Events. Kontextreiche Telemetrie.
Das Ergebnis sind nicht nur Kosteneinsparungen, obwohl die erheblich sind. Es ist ein fundamental anderes Operating Model. Eure Analysten hören auf, Daten-Hausmeister zu sein, und fangen an, Ermittler zu sein.
Der Mindset Shift für 2026
Die wichtigste Veränderung ist nicht technisch. Sie ist strategisch.
Hört auf, in Tools zu denken. Fangt an, in Pipelines zu denken. Wenn eure Sources von euren Destinations entkoppelt sind, gewinnt ihr etwas zurück, das die meisten Unternehmen still und leise verloren haben: Wahlfreiheit. Die Freiheit, Daten an die beste Analytics Engine für den Job zu routen, nicht an die, in der ihr gefangen seid. Die Freiheit, Kosten auf Architekturebene zu steuern, nicht über schmerzhafte jährliche Nachverhandlungen.
Jeder Euro, den ihr für Data Ingestion ausgebt, sollte an ein Outcome gebunden sein. Wenn nicht, investiert ihr nicht in Security. Ihr subventioniert eine Mülldeponie.
Bereit, loszulegen?
Kontaktieren Sie uns für eine kostenlose Beratung und erfahren Sie, wie wir Ihr Sicherheitsprogramm verbessern können.